

¿Sabe usted qué son bases de datos y algoritmos? Probablemente su respuesta sea afirmativa. Si tiene acceso a una conexión de Internet, ambos conceptos no serán ajenos a su cotidianidad.
Al menos tendrá una noción sobre lo que son, cómo funcionan y qué permiten hacer. Con regularidad hay información al respecto, como este artículo de The Economist que, en mayo de 2017, explicaba por qué “El recurso más valioso del mundo ya no es el petróleo, sino los datos”.
Sabrá que algunos de los datos que generamos desde nuestros dispositivos conectados a la web son recolectados masivamente y que son “oro” para empresas como Netflix, Facebook, Google, Amazon, Apple y otras, que los analizan para conocer mejor nuestros gustos y patrones de consumo.
También sabrá que existe un gran debate por la forma en que debe regularse ese poder de controlar tanta información a nivel global.
El uso de bases de datos y de algoritmos no es- ni debe ser- domino único para los negocios de los gigantes de Internet o para quienes tengan recursos humanos y tecnológicos para explotarlos.
En los últimos cinco años, el uso de bases de datos y de algoritmos se ha extendido también entre ciudadanos y organizaciones. Principalmente las que impulsan la apertura masiva de información de interés público (open data) para un análisis y difusión más transparente de la gestión del Estado y gobiernos del orbe.
En Periodismo, ¿para qué sirven las bases de datos y los algoritmos? ¿por qué es importante que los periodistas aprendamos a comprenderlos y usarlos?
Porque en esa dupla, básicamente, descansan los “superpoderes” que los periodistas necesitamos para investigar más y mejor las andanzas del poder en el mundo.
Hace unos meses, durante una conferencia en la universidad Alberto Hurtado en Santiago de Chile, ejemplificaba cómo los datos están presentes en todo lado y cómo se pueden convertir en un insumo para potenciar las posibilidades de la investigación periodística.
Mostré esta foto

Conté que la imagen la había tomado en el aeropuerto de Tocumen, en Panamá, el 17 de octubre de 2016.
“Mientras hacía escala para abordar el avión que me traería hasta Santiago, hice lo que siempre hago: buscarme un café con leche”, le dije al público.
Después de unos segundos de silencio, pregunté a los asistentes – la mayoría futuros colegas- cuántos creían en la veracidad de esa historia, por qué la darían por cierta y si confiaban en la fuente.
Ante el silencio y la duda, le propuse a la audiencia hacer lo debido en el buen periodismo: verificar mi afirmación, examinar la evidencia ofrecida por la metadata que contenía la foto en cuestión.
¿Qué es la metadata?, se preguntará. Es lo que a simple vista no se ve, pero describe la información y el contenido que está detrás de los datos.
Para comprenderlo mejor, le muestro lo que estaba “oculto” (los metadatos) de la imagen de la misteriosa taza de café.
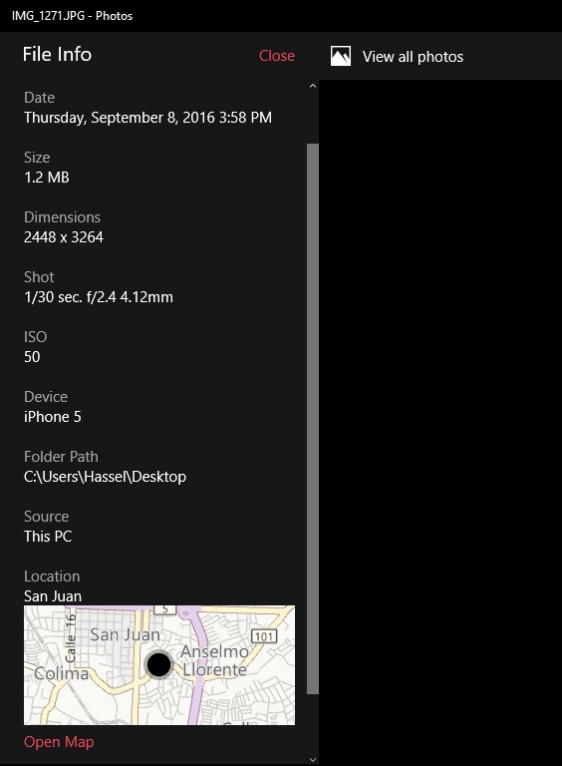
Como ve, los metadatos de esta imagen dicen más de lo que se veía a simple vista, empezando por la fecha. La foto se había tomado un mes y medio antes del día del vuelo a la capital chilena.
Además, incluía la ubicación geográfica, que mostraba que la imagen se tomó en San José de Costa Rica, en la cafetería de La Nación, – donde laboro-, no en el aeropuerto de Panamá.
Antes de dar el rotundo veredicto de falsedad, recordé a mis futuros colegas, que nos llamamos periodistas porque siempre debemos reportear, salir a la calle. Los datos son complemento de ese reporteo.
En mi afirmación había una segunda “mentira” que los metadatos no podían poner al descubierto. Había dicho que, para llegar a Chile, hice una escala en Panamá.
La veracidad de ello solo se podía confirmar pidiendo una copia de mi itinerario de vuelo y entrevistando a la coordinadora administrativa de la Universidad, quien, sin duda, diría que no hice escala en Panamá, sino en Lima, Perú.
Es decir, los métodos de investigación tradicional siguen -y seguirán siendo- fundamentales en periodismo.
La era de los datos masivos y el periodismo
Ese caso de la fotografía es solo un ejemplo de la inmensa cantidad de datos que los humanos y nuestras máquinas generamos a cada segundo y son susceptibles de análisis.
Solo el año pasado, la cantidad de información que circuló por la red alcanzó la siguiente cifra:
1,2 zettabytes o 1.200.000.000.000.000.000.000 bytes
Un byte es la unidad mínima de almacenamiento de la información, suficiente para codificar un número o una letra.
Aunque 1,2 zettabytes de tráfico de información por la web parezca una cifra inimaginable, en cinco años se triplicará (3,3 zettabytes), primordialmente por el consumo de video en los dispositivos móviles, de acuerdo con un informe de la compañía Cisco.
Vivimos en una era donde el volumen de datos disponibles en Internet crece exponencialmente todos los días y su almacenamiento se abarata constantemente, eso ha favorecido el desarrollo del llamado big data y la consolidación de los científicos de datos.

¿Qué es Big Data?
En una definición muy general, big data es el almacenamiento masivo de datos. Es lógico preguntarse: ¿Cuál es el volumen aproximado de datos necesario para decir que algo es big data?
La respuesta es relativa. Depende de los propósitos de cada quien y de si el tamaño de la data es parte del problema. Para algunos, procesar 1.000 gigabytes de información no es un lio, para otros procesar un gigabyte sí puede serlo.
Ahora bien, Big data por sí misma carece de sentido si solo se almacenan datos sin propósito y, en consecuencia, se cree que el volumen por administrar siempre debe ser exorbitante.
Almacenar información tiene sentido solamente si se analiza con las técnicas pertinentes para deducir de ella patrones de comportamiento de personas o máquinas. O bien, nos permite hacer pronósticos sobre su comportamiento futuro.
El objetivo es simple: extraer información y conocimiento de los datos para tomar decisiones.
“Para mí, big data es un término menor, ciencia de datos (data science) es el término importante. Big data es acumulación de datos, ciencia de datos es lo que da valor a los datos. Es ahí donde el poder explicativo de las ciencias sociales cobra su verdadero valor”, afirma el científico de datos costarricense Michael Herradora.
¿Qué es un algoritmo?
En toda esta cadena de análisis de datos, los algoritmos tienen un papel vital.
Un algoritmo es una serie de pasos, lógicos y ordenados, que permiten encontrar la solución a un problema.
Los ingenieros, por ejemplo, analizan el problema, diseñan una solución paso a paso y ejecutan el código sobre los datos en cuestión.
Hay algoritmos de minería de datos o extracción de datos desde internet, hay algoritmos que aprenden de la información que usted va dejando y con ella predicen, con cierto grado de confianza, si a usted le gustaría o no tal película, por citar un caso.
Le cuento todo esto con un objetivo: que comprenda que, quiera o no, los datos están en todas partes y alguien siempre los está analizando. Se están usando para hacer negocios –lícitos e ilícitos- y también para ejercer una cuestionable vigilancia sobre la humanidad.
En la Edad Media se hablaba de una sociedad teocéntrica, el centro de la humanidad era Dios. En el Renacimiento, el centro de la humanidad era el hombre, su propia creación y pensamiento. En la actualidad se podría decir que el centro de la humanidad se enrumba hacia los datos que ella misma genera. Y esto, evidentemente, es para su propio bien o su propio mal.
SOS, soy periodista y tengo una base de datos
¿Y cómo se engancha todo esto de las bases de datos, el análisis y la investigación con el periodismo?
Los periodistas deberíamos de desarrollar el mismo músculo intelectual y tecnológico que existe en empresas y en ciertos gobiernos para recopilar y analizar datos. Claro está para aplicarlo para el bien de la sociedad.
No desarrollar esas habilidades para manejar datos provocaría que el poder y el conocimiento se siga concentrando en pocas manos, que descaradamente se oculte la corrupción y la desigualdad que nos golpea como sociedad.
La magnitud de esas implicaciones las comprendieron dos periodistas alemanes a quienes, en 2015, les llegó este mensaje:

¿Qué pasaría si usted recibe una oferta de información y primicia como esta? ¿Qué pasaría hoy si usted tiene acceso a una base de datos que oculta algo importante y que debe de ser revelado periodísticamente? ¿Está listo para asumir el reto? ¿Sabría cómo enfrentarlo, cómo investigarlo y extraer el conocimiento que necesita de esos datos?
Estos dos periodistas alemanes sí, sí sabían cómo hacerlo. Sabían cómo manejar y analizar bases de datos. Ya lo habían hecho en el pasado.
Pero aun así, ante la dimensión de lo que revelaban los datos, decidieron compartirlos con un equipo del Consorcio Internacional de Periodistas de Investigación (ICIJ). El resto es historia y usted la conoce lo suficiente: Panama Papers.
Le muestro esta filmina solo para que tenga una idea de la cantidad de datos que estructuró el equipo de ingenieros de ICIJ para hacerlos digeribles y facilitar que los periodistas los usaron como insumo en este proyecto global.
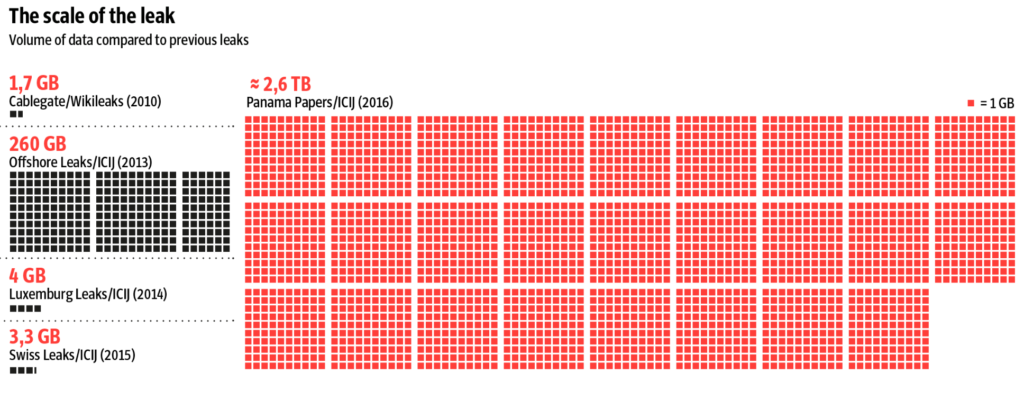
Es una cantidad de datos impresionante, sin duda, pero, aunque es una de las más irrefutables muestras del poder que las bases de datos y los algoritmos dan al periodismo, no define, exclusivamente, a lo que conocemos como periodismo basado en análisis de datos.
Este periodismo no se ubica solo en términos de análisis de datos masivos. Como escribí al principio qué son o qué no son datos masivos es relativo y sobre todo en Periodismo.
Para muestra basta con ver los distintos volúmenes de datos que el propio ICIJ ha manejado para anteriores proyectos de impacto mundial.
El volumen de los datos no es lo único extraordinario en una investigación. Lo sorprendente es lo que el periodista es capaz de revelar por medio del análisis de una base de datos, tenga esta cientos o billones de registros. Lo que importa es el impacto que ese análisis tenga en la sociedad.
Por ello es crucial que el periodista tenga los conocimientos para analizar bases de datos, sin importar su tamaño. Lo peor que le puede pasar a un reportero es quedarse frio, contemplando una base de datos con los brazos cruzados porque, simple y sencillamente, no sabe cómo procesarla –tan siquiera- en una hoja de cálculo.
Las bases de datos como insumo periodístico
En este punto quiero darle un par de ejemplos de cómo, dentro de la Unidad de Datos de La Nación Costa Rica, usamos los datos. Insisto, nos enfocamos más en el impacto que en el volumen de los datos.

Esta imagen es parte de una aplicación de noticias que desarrollamos para las elecciones municipales de febrero de 2016. Se elegían 81 alcaldes y participaban 605 candidatos. Los investigamos a todos y contamos a los votantes quienes eran.
Este video explica, rápidamente, en qué consiste la aplicación.
¿Cómo lo hicimos?
Durante cinco meses, un equipo de cinco periodistas, nos dimos a la tarea de recolectar o solicitar toda la información pública disponible sobre los 605 candidatos.
Recopilamos las actas de certificación de candidaturas del Tribunal Supremo de Elecciones, los antecedentes judiciales y las sanciones o inhabilitaciones para ejercer cargos públicos de la Contraloría General de la República. También los montos de las deudas de los candidatos con la seguridad social, tanto las personales como de sus empresas. Sin dejar por fuera su currículo y su experiencia política y comunal.
La mayoría de los datos recolectados venían en PDF y Word, muchos más estaban en expedientes de papel. Otros los recogimos por medio de entrevistas y los menos venían en hojas de Excel.
Todos esos miles de datos se sistematizaron y estructuraron en seis bases de datos. La información de esas bases de datos se sometió a una exhaustiva verificación. Ese es un principio angular del Periodismo y el Periodismo de datos no es la excepción.
Los números nunca deben de ser tomados como una verdad absoluta, si no los chequeamos severamente pueden inducirnos a errores garrafales.
Seguidamente, hicimos los análisis: las entrevistas a los datos para extraer de ellos las conclusiones que nos permitieron afianzar la evidencia para cada una de las investigaciones que presentamos. Salimos a la calle, entrevistamos a los protagonistas de esas historias y escribimos.
Pero analizar datos, investigar y escribir es solo una parte del trabajo. Paralelamente a ese proceso ocurrían otros.
Esas seis bases de datos que construimos para el proyecto iban, automáticamente, al almacén de datos de ingeniería de la sección. Allí se daba el proceso de relación de datos y de creación de algoritmos para que esas bases de datos, automáticamente, alimentaran la información que contendría la aplicación interactiva de noticias.
¿Qué hizo el ingeniero en ese almacén?
- Relacionar toda la información de esas seis bases por medio de campos llave. ¿Qué es un campo llave? Es un número único que se le asignó a cada candidato, en este caso su número de cédula. El número de cédula estaba presente en todas las bases de datos que hicimos y así teníamos certeza de que toda la información que se atribuía a cada candidato era correcta.
- Las seis bases de datos obviamente iban siendo modificadas y editadas en el proceso. El ingeniero creó una solución para que esos cambios se incorporaran en tiempo real a su sistema de gestión de datos. Así también evitábamos cometer errores de atribuir delitos o sanciones a personas que luego corroboramos no los cometieron.
- Otro algoritmo para este proyecto fue el que permitió la extracción automatizada y en tiempo real de los montos adeudados por los candidatos a la seguridad social, tanto personales como en sus empresas. Para este, un pequeño robot iba a la página web del Seguro Social y consultaba, automáticamente, los números de cédula del candidato o el número de su sociedad. Los resultados los almacenaba en un documento con formato txt, que luego convertíamos en una hoja de cálculo. Aquí no había posibilidad de error, si alguien no había pagado minutos antes de publicar nuestra investigación, aparecería como moroso y punto.
- Toda esa información se convertía y actualizaba automáticamente en cientos de documentos de html y Json (un formato liviano para descripción de datos que lo lee cualquier lenguaje de programación). Así se alimentaba de data a la aplicación y se garantizaba que la carga de datos no fuera lenta.
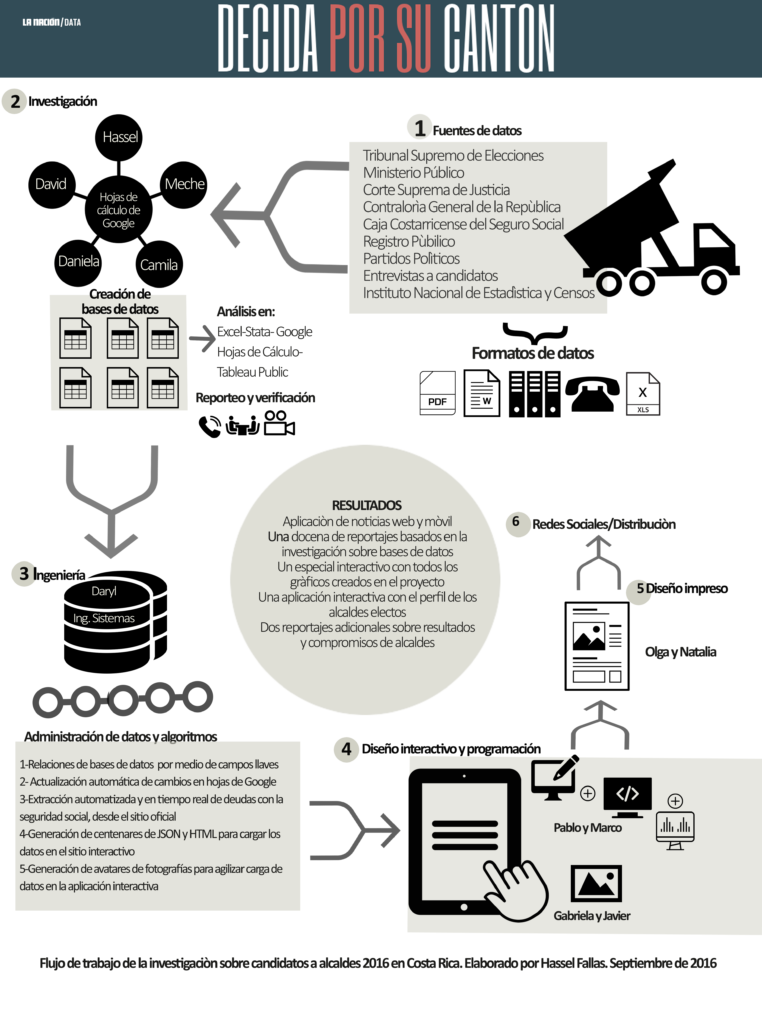
Toda esa información llegaba a manos de los diseñadores y programadores interactivos, quienes estaban diseñando la experiencia de usuario de la aplicación y generando los gráficos interactivos que acompañarían las conclusiones de los análisis de datos que darían sustento a nuestros reportajes.
De esta parte interactiva se nutría el área de diseño impreso y de distribución en redes sociales de La Nación.
El resultado final fue la aplicación de noticias y esta serie de publicaciones basadas en los datos recopilados y analizados.

En este caso, las bases de datos fueron todo el Sistema Circulatorio de una investigación. Todo giró alrededor de ellas. Sin embargo, no siempre en los proyectos periodísticos ocurre así.
A veces las bases de datos son solo una arteria más que lleva sangre para oxigenar la investigación. A veces el corazón de una investigación está más en un método tradicional, pero enriquecido y fortalecido por bases de datos, que buscamos o creamos, para amplificar las revelaciones que haremos.
En agosto de 2016, publicamos en el diario una investigación que demostró cómo millones en recursos públicos para educar al sector cooperativo alimentan los negocios de empresas privadas del que se supone es el centro que debe de encargarse de capacitar al sector.
También demostramos que, en tres décadas, nadie en el Estado ha supervisado cómo se usa parte de esa plata.
Para llegar contundentemente a esas conclusiones tuvimos que recurrir a métodos de investigación más tradicionales: bucear dentro de más de 7.000 folios de documentos que nos permitieron reconstruir buena parte de la historia y decisiones de esta cooperativa.
Pero decidimos que la cronología de hechos y pruebas la haríamos en formato de bases de datos, con números de prueba, número de expediente, identificación de fotos de documentos etc.
Este método nos permitió relacionar información, nos facilitó la redacción y la verificación de pruebas para blindar la investigación. El impacto fue grande durante una semana. Se abrió una investigación en el Congreso, se pidió frenar los giros de dinero a la cooperativa, entre otras reacciones.
Para complementar los hallazgos construimos y analizamos dos bases de datos que evidenciaron los otros negocios que el cuestionado centro tiene con el Estado y cómo el partido Liberación Nacional, el principal propulsor de leyes y recursos a favor de ese Centro, también lo nutría por medio de la deuda política.
La investigación se llamó Negocios cooperativos y puede consultarla aquí.

Por ejemplos como esos dos que acabo de presentarles es que a mí me gusta definir al Periodismo de Datos como:
Investigar un tema de interés público apoyándose en el análisis de bases de datos, contengan estas millones, miles o decenas de registros. La publicación puede incluir visualizaciones de datos, aplicaciones de noticias y multimedia.
Muy a menudo me preguntan qué se necesita para ser periodista basado en análisis de datos. Básicamente vocación para cumplir siete objetivos:
- Tener clara su misión de velar por un real interés público.
- Poseer aptitud para investigar. Probar y poner en evidencia hechos que están ocultos deliberadamente por alguien en una posición de poder.
- Aprender a analizar bases de datos.
- Aprender a resolver problemas, comprendiendo que muchas veces la solución no la da una computadora sino una mezcla de técnica, conocimiento de estadística o matemática básica, pero sobre todo de mucho olfato reporteril.
- Entender cómo funciona la lógica de la ingeniería en sistemas y de la programación para explicar un problema y cómo visualizar una potencial solución.
- Entender cómo funciona el cerebro de un diseñador. Un periodista debe de tener una idea clara de lo que quiere comunicar con los datos.
- Trabajar en equipo. En periodismo de datos ningún periodista es una isla. Aun cuando usted crea que están solos en esto, tendrá que buscar ayuda de alguien para resolver un problema.
En ese sentido, el periodismo hace mucho tiempo dejó de ser solo una cosa de periodistas. En el equipo con el que trabajo en Costa Rica, hay periodistas que optamos por especializarnos en Economía, Inteligencia de Negocios, Minería de Datos y Estadística. Hay un diseñador que empezó diseñando con lápiz y papel y luego aprendió a programar. Finalmente, un ingeniero en sistemas que no solo es capaz de administrar bases de datos, sino de programar (front end)
A lo largo de este artículo he hablado de la omnipresencia de los datos en casi todo lo que hacemos hoy en día. De los usos que como humanidad les estamos dando y de la responsabilidad que como periodistas tenemos de aprender a usarlos como una fuente más para revelar aquello que debe de ser denunciado en la sociedad.
Cierro con una frase de un escritor de Ciencia Ficción que no es una ficción:
“Creo que las tecnologías son moralmente neutrales hasta que las aplicamos. Es solo cuando las usamos para el bien o para el mal que se conviertan en buenas o malas”, William Gibson, escritor.
Usted, ¿de qué lado quieren estar?