Visibilizando la violencia y discriminación contra la población LGBTIQ+
Guía de aprendizaje para la recolección, análisis y uso de datos para prevenir y atender la violencia a causa de orientación sexual e identidad de género
Parte del proyecto: Mapeo para el mejoramiento de datos sobre violencia por orientación sexual e identidad de género Un análisis sobre: Costa Rica, El Salvador, Guatemala, Honduras y Nicaragua
Esta guía está disponible bajo una licencia Creative Commons Attribution 4.0. Cite cualquier uso de ella como: Fallas, Hassel. ILDA/HIVOS (2021). Guía de aprendizaje para recolección, análisis y uso de datos para prevenir y atender la violencia a causa de orientación sexual e identidad de género.
Objetivo general del curso
Propiciar en les activistas y organizaciones LGBTIQ+ el aprendizaje y aplicación de técnicas de recopilación, estructura, análisis y uso de datos para prevenir y atender la violencia a causa de orientación sexual e identidad de género en Costa Rica, El Salvador, Honduras, Guatemala y Nicaragua
Objetivos específicos
Aprender a recolectar y sistematizar información en hojas de cálculo de Google sobre casos de violencia a personas LGBTIQ+ a partir de entrevistas, documentos públicos, noticias, portales web oficiales y otras fuentes.
Utilizar técnicas y herramientas de análisis de datos para entrevistar bases de datos y extraer de ellas conclusiones de interés de las organizaciones para incidencia y evidencia de casos de violencia.
Implementar principios básicos de comunicación/storytelling con datos para producir materiales o informes que contribuyan a evidenciar, prevenir y atender la violencia a causa de orientación sexual e identidad de género.
Software del curso
Hojas de cálculo de Google. Por ello es indispensable que tengas o abras una cuenta de Gmail y utilices la aplicación Drive que se accede desde ese tipo de correo electrónico.
Las hojas de cálculo usadas para este curso pueden descargarse desde este URL
Una vez que accedas al archivo desde tu cuenta de Gmail, haz una copia para guardarlo en tu Drive y poderlo manipular según las instrucciones siguientes
Temas del curso
ABC de los datos
¿Qué es un dato?
Tipos de datos
¿Qué es una variable?
¿Qué es una hoja de cálculo?
Introducción de datos en hojas de cálculo
¿Qué es, para qué sirve y cómo hacer un diccionario de datos?
Ejercicio para distinguir variables relacionadas con violencia y discriminación hacia personas LGBTIQ+
Estandarización de datos
Errores frecuentes en bases de datos, ¿cómo corregirlos?
Errores de tipografía
Formato de fechas
Separar texto de números
Detectar duplicados
Listas de elementos para validar datos
Ejercicio práctico
Análisis de datos
Técnicas para extraer información útil de los datos
Uso de filtros para encontrar respuestas rápidas en bases de datos
Creando tablas dinámicas para cruzar información de dos o más variables de interés
Ejercicio práctico
Gráficos para analizar y comunicar conclusiones de los datos
Gráficos y conceptos esenciales para presentar información basada en datos
Herramientas en línea para crear gráficos
Ejercicio práctico
Uso y comunicación basada en datos
Técnicas de storytelling para crear mensajes a partir de conclusiones extraídas de los datos
I Parte: Introducción al curso
¡Bienvenide al curso: Recolección, análisis y uso de datos para prevenir y atender la violencia a causa de orientación sexual e identidad de género!
Este capacitación te introducirá en las temáticas relacionadas con el proceso de análisis de datos, yendo -paso a paso- por la ruta de las técnicas de la recolección de datos, la estructura de información desordenada, su exploración y, finalmente, la visualización de datos para comprender y evidenciar conclusiones de impacto para la audiencia por medio de gráficos.
El primer módulo de este programa se denomina el ABC de los datos y en él se responderán cuatro preguntas esenciales para comprender qué es un dato y sistematizarlo en una hoja de cálculo. Además, realizarás un ejercicio de comprensión y aplicación práctica del tema.
Preguntas por resolver:
¿Qué es un dato?
Tipos de datos
¿Qué es una variable?
¿Qué es una hoja de cálculo?
¿Cómo introducir datos en una hoja de cálculo?
¿Cómo estructurar una base de datos a partir de la recolección manual de información?
¿Qué es, para qué sirve y cómo hacer un diccionario de datos?
Ejercicio para distinguir variables relacionadas con violencia y discriminación hacia personas LGBTIQ+
¿Qué es un dato?
Desde la teoría, un dato es una representación simbólica (numérica, alfabética, algorítmica, espacial, etc.) de un atributo o variable cuantitativa o cualitativa. Debe ser estructurado, comprensible para ser procesado por una computadora. En simple, un dato es un valor que se le asigna a cualquier cosa o persona. Ese valor, por lo general, suele ser un número o un texto.
Ejemplos:
El nombre de una persona: Manuel, Mercedes.
La edad: 24, 27
¿Qué tipos de datos hay?
Desde el punto de vista estadístico hay datos cualitativos y cuantitativos.
Datos cuantitativos: Son números fundamentalmente
Ejemplos:
La cantidad de años, meses y días transcurridos sin justicia para un crimen de odio o prejuicio contra una persona LGBTIQ+
La edad en años cumplidos de las personas LGBTIQ+ víctimas de violencia o discriminación
La fecha en que ocurrió el crimen de odio
Datos cualitativos: Datos que se representan con letras, texto.
Ejemplos:
Las categorías que engloba la orientación sexual: Gay, lesbiana, bisexual
Las categorías que engloba la identidad de género: Hombre, Mujer, no binario, binario, trans, cisgénero, sin género
Las categorías que engloba la expresión de género: Masculino, femenino, andrógina, travesti
Las categorías que engloba el Tipo de violencia: física, sexual, psicológica, patrimonial
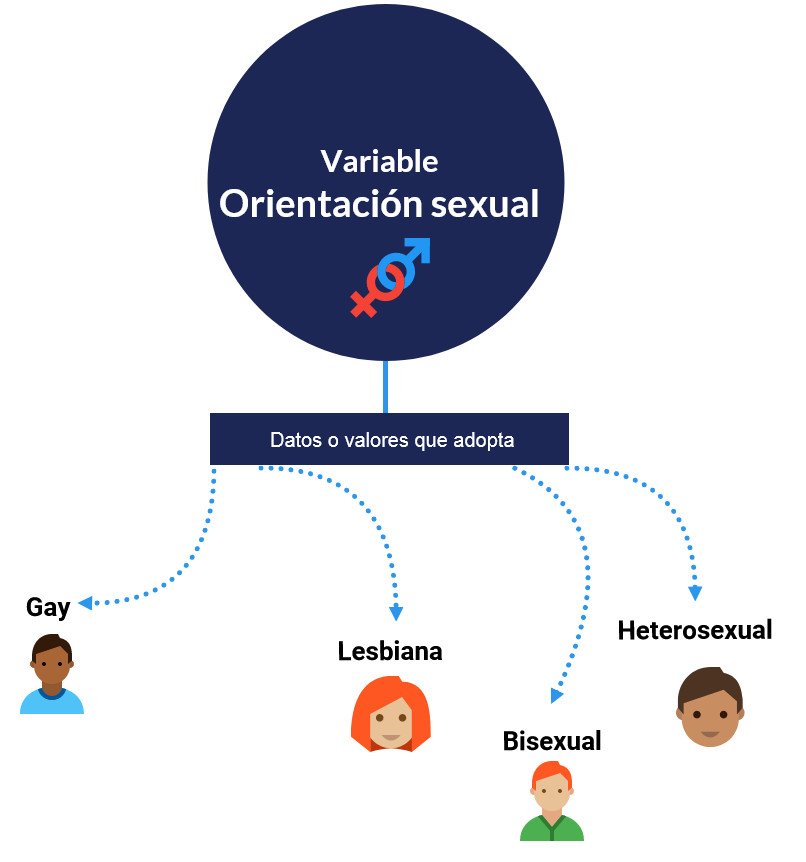
¿Qué es una variable?
Una variable estadística engloba cada uno de los valores o categorías que representan los datos y se expresan como características o cualidades que poseen los individuos de una población determinada.
Ejemplo:
¿Qué es una hoja de cálculo?
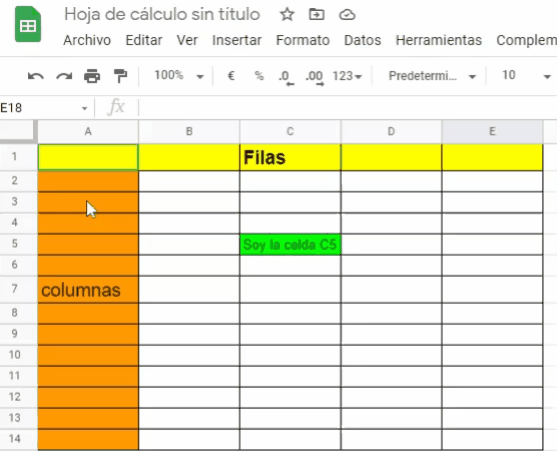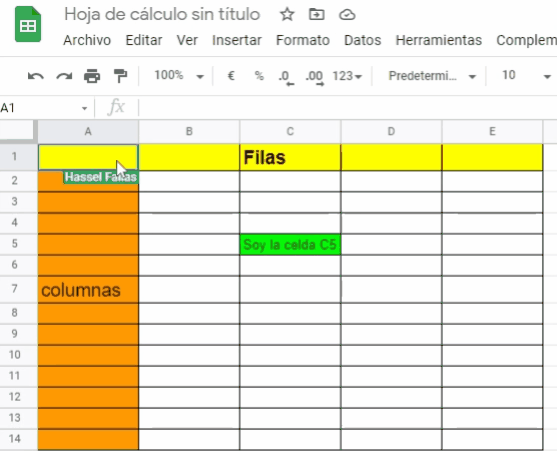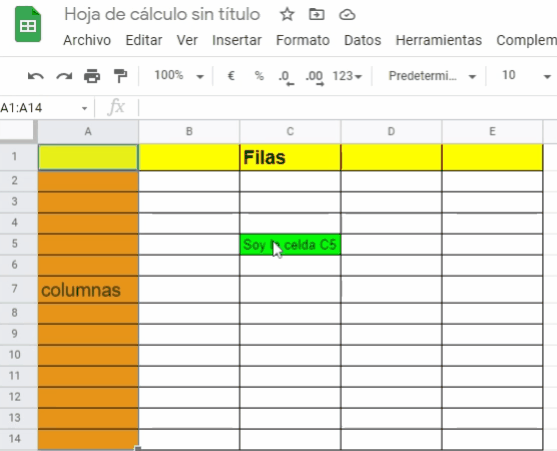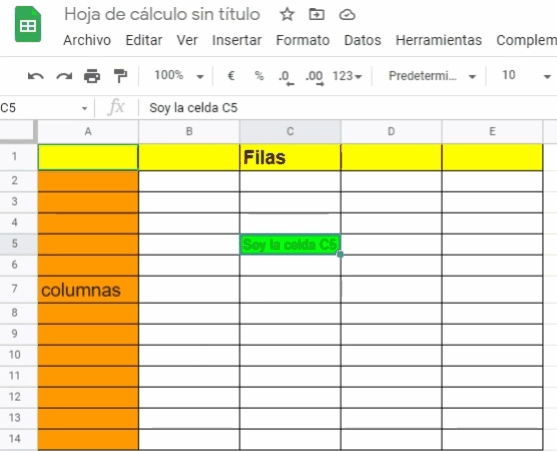
Es un documento para introducir y/o manipular datos alfanuméricos (números y texto) dentro de celdas que se organizan dentro de una matriz de filas y columnas.
Fila: Es un grupo de celdas que se agrupan horizontalmente de izquierda a derecha en una hoja de cálculo
Columna: Es un grupo de celdas que se agrupan verticalmente desde arriba hacia abajo en una hoja de cálculo
Celdas: Es la intersección entre una fila y una columna. El espacio donde colocamos la información alfanumérica de interés
¿Cómo introducir datos en una hoja de cálculo?
Para introducir datos correctamente en una hoja de cálculo deben seguirse dos pasos:
La lógica de su estructura, conformada por las columnas, las filas y las celdas.
Siguiendo esa lógica, cada columna estará conformada por una variable estadística y los valores o categorías que engloba se escriben en cada una de las celdas que la conforman de manera vertical.
Ejemplo:
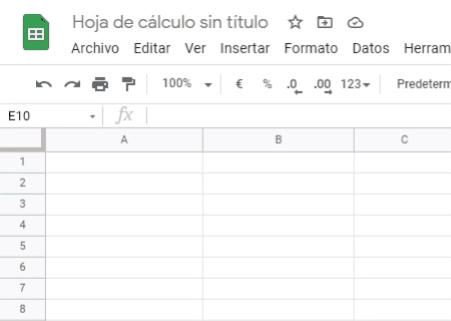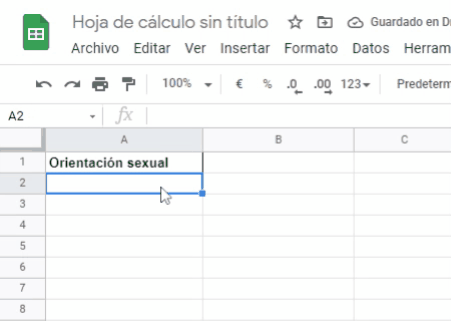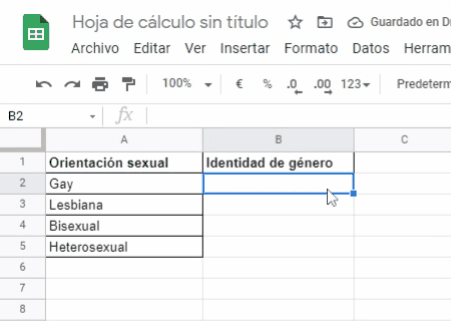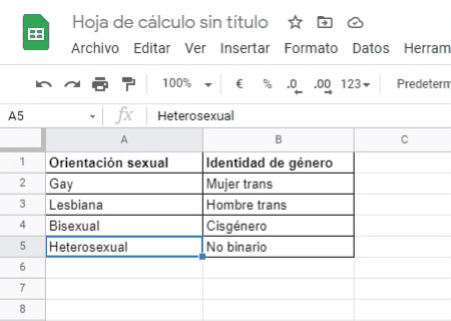
Como observas en el video de arriba, la columna A corresponde a la variable Orientación sexual. El nombre de la variable Orientación sexual se escribe en la celda A1. Los valores o categorías que engloban a la variable de Orientación sexual: Gay, Lesbiana, Bisexual, Heterosexual, se digitan también en la columna A, específicamente en las celdas: A2, A3, A4 y A5.
Debes seguir la misma lógica para la variable Identidad de Género, pero a partir de la columna B y sus celdas. Y así, consecutivamente para todas las variables que desees incluir en tu base de datos.
Estructurar una base a partir de recolección manual de información
Ahora que ya tienes claras las nociones de dato, variable estadística y cómo ésta se descompone en distintas categorías o valores para asignar características o cualidades a los individuos de una población determinada, aprenderás a estructurar toda esa información en una base de datos.
¿Qué es una base de datos?
Es un conjunto de datos pertenecientes a un mismo contexto y almacenados sistemáticamente para su posterior consulta, análisis y uso.
Para crear una base de datos como la que muestra la imagen de arriba es necesario recurrir a la recopilación de datos de diferentes fuentes de información: Noticias publicadas por la prensa, comunicados de la Policía, entrevistas a víctimas y familiares, por citar algunas.
¿Cómo crear una base de datos recopilando manualmente la información?
Pasos:
Determina primero qué variables quieres recopilar en tu base
Establece los posibles valores o categorías en las que cada variable se desglosará
Identifica las fuentes potenciales que revisarás para extraer de ellas la información que necesitas para desglosar cada variable
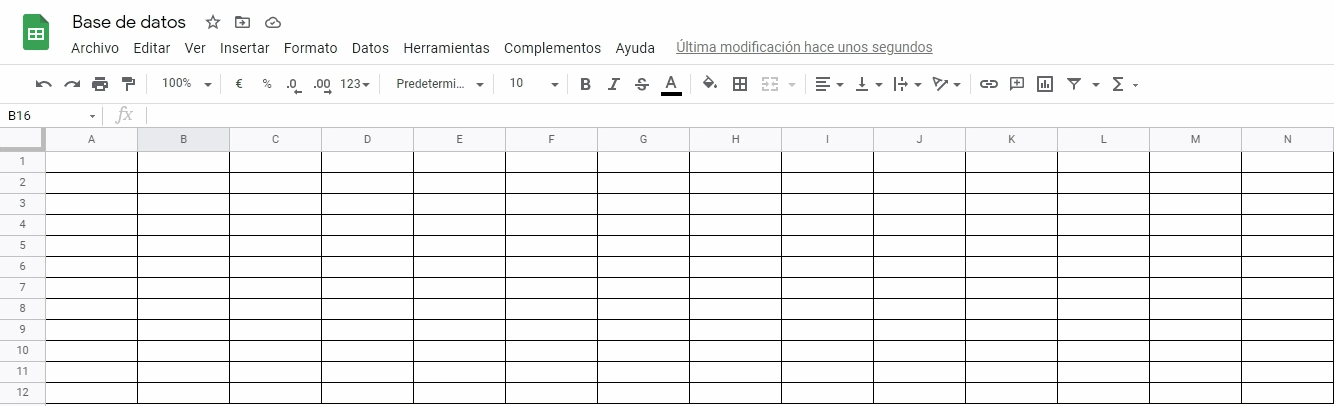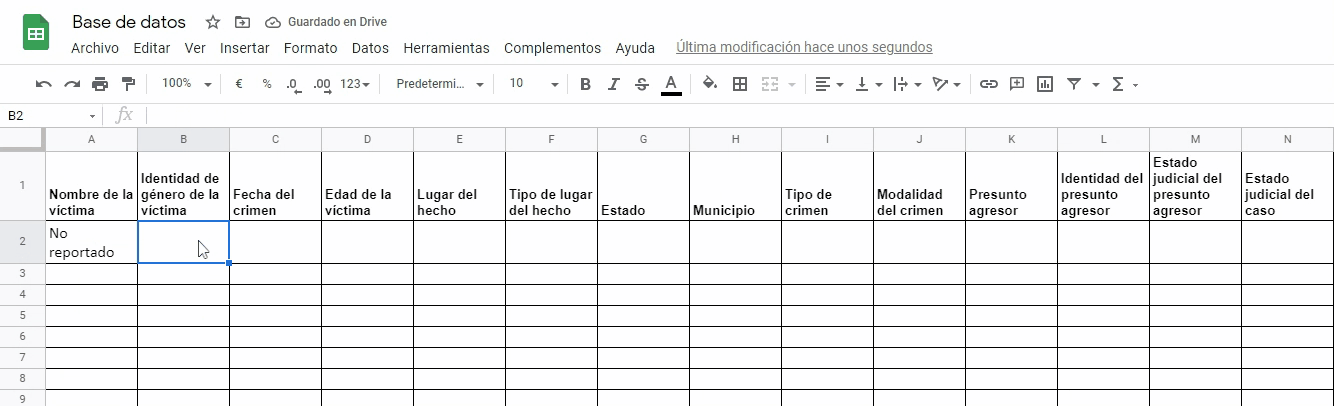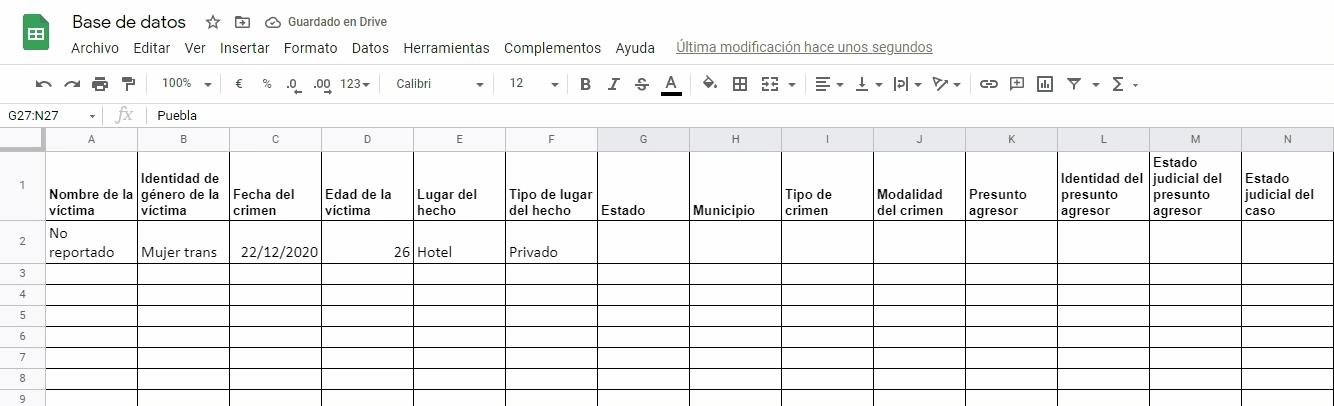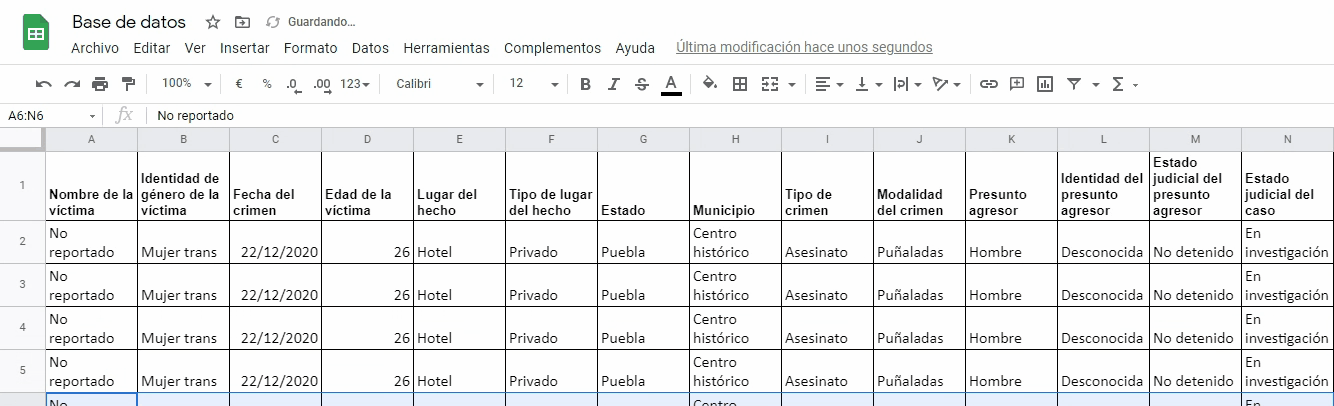
Ejemplo: Ana y Francella son dos mujeres trans y activistas que están documentando casos de crímenes de odio o prejuicio a causa de orientación sexual e identidad de género. Su fuente son notas de prensa. De esas notas quieren extraer información para sistematizar en una hoja de cálculo y construir una base de datos útil para evidenciar los casos, analizar la información y extraer de ellas conclusiones que les ayuden a hacer incidencia social y política para exigir respeto a sus derechos humanos. Ana y Francella empiezan por leer cada noticia que han recopilado:
Luego de la lectura, determinan que el texto de cada noticia suele contener detalles en común que pueden sistematizarse como variables dentro de una base de datos:
Nombre de la víctima
Identidad de género de la víctima
Fecha del crimen
Edad de la víctima
Lugar del hecho
Tipo de lugar del hecho
Estado
Municipio
Tipo de crimen
Modalidad del crimen
Presunto agresor
Identidad del presunto agresor
Estado judicial del presunto agresor
Estado judicial del caso
También determinan dentro del texto de la noticia cuáles son los valores o categorías en las que cada variable se desglosa:
Nombre de la víctima: No reportado
Identidad de género de la víctima: Mujer trans
Fecha del crimen: 22-12-2020
Edad de la víctima: 26
Lugar del hecho: Hotel
Tipo de lugar del hecho: Privado
Estado: Puebla
Municipio: Centro histórico
Tipo de crimen: Asesinato
Modalidad del crimen: Puñaladas
Presunto agresor: Hombre
Identidad del presunto agresor: Desconocida
Estado judicial del presunto agresor: No detenido
Estado judicial del caso: En investigación
Tanto la identificación de variables como los valores o categorías en que cada una de ellas se desglosa, son sistematizadas en una hoja de cálculo por Ana y Francella; tal y como se muestra en el video adjunto:
Ejemplo de sistematización manual de datos:
Francella y Ana repiten ese proceso de lectura de noticias, extracción de variables y de los valores que éstas adoptan en otros 50 casos. Al final de la semana, han recopilado y sistematizado una importante cantidad de información que les ayudará a cumplir su propósito de evidenciar los casos de violencia contra personas trans, analizar la información y extraer de ella conclusiones que les ayuden a hacer incidencia social y política para exigir respeto a sus derechos humanos.
¿Qué es, para qué sirve y cómo hacer un diccionario de datos?
Un diccionario de datos explica lógicamente de qué trata cada una de las variables y los valores y/o categorías en las que ellas se desglosan.
Crear un diccionario de datos para explicar las definiciones que incumben a esas variables y sus categorías es fundamental para:
Dejar claro a las personas usuarias de tu base de datos -dentro o fuera de tu organización- las definiciones que deben entender para cada variables y categoría
Así no dejas nada a la peligrosa suposición
Te ayuda a tener claridad de qué datos son los que debes recolectar y por qué
Es vital también para estandarizar criterios a la hora de introducir los datos en tu hoja de cálculo
Te da claridad y precisión para sacar conclusiones de utilidad para tus análisis y reportes de incidencia.
Ejemplo: Ana y Francella han determinado que para construir su base de datos de casos de crímenes de odio o prejuicio a causa de orientación sexual e identidad de género utilizarán 14 variables distintas:
Nombre de la víctima
Identidad de género de la víctima
Fecha del crimen
Edad de la víctima
Lugar del hecho
Tipo de lugar del hecho
Estado
Municipio
Tipo de crimen
Modalidad del crimen
Presunto agresor
Identidad del presunto agresor
Estado judicial del presunto agresor
Estado judicial del caso
Ahora, a la par de la hoja de cálculo que contiene esa estructura, añadieron otra hoja para crear el diccionario de datos que permitirá a otras activistas de su organización recolectar y sistematizar datos con la claridad de que todas están usando las mismas definiciones y comprendiendo los mismos conceptos.
Ahora que Ana y Francella tienen su base de datos recopilada manualmente y también su diccionario de datos, les han surgido varias dudas sobre la veracidad de algunos datos incluidos. Por esa razón, desean aplicar a su archivo un proceso de Fact-checking o comprobación de hechos.
En esta segunda parte del curso aprenderás de estandarización o limpieza de datos, uno de los procesos claves para generar datos con la calidad necesaria para que las conclusiones de tus análisis realmente sirvan para prevenir y atender la violencia a causa de orientación sexual e identidad de género.
La estandarización o limpieza de datos es hacer un detallado proceso de inspección de nuestra base de datos para detectar inconsistencias, depurar la información y asegurarnos de que los datos con los que vamos a trabajar son precisos. Es decir: que en ellos no hay errores que nos conduzcan a conclusiones equivocadas.
La limpieza de datos es un proceso integral para detectar en un archivo de datos: Errores de digitación, ortográficos y de tipografía, por ejemplo. También para corregir formatos de fechas y números, por ejemplo.
Errores frecuentes en bases de datos
Errores de tipografía
Formato de fechas
Detectar duplicados
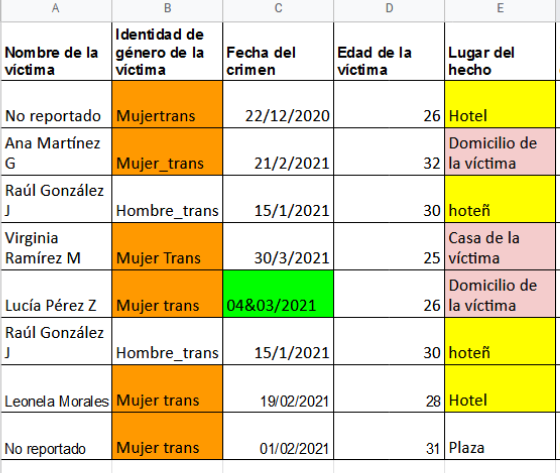
Ejemplo: Ana y Francella han avanzado en la sistematización de variables y datos relacionados con crímenes de personas LGBTIQ+. Ahora deben depurar su base de datos ya que han encontrado algunos errores, como los citados de seguido:
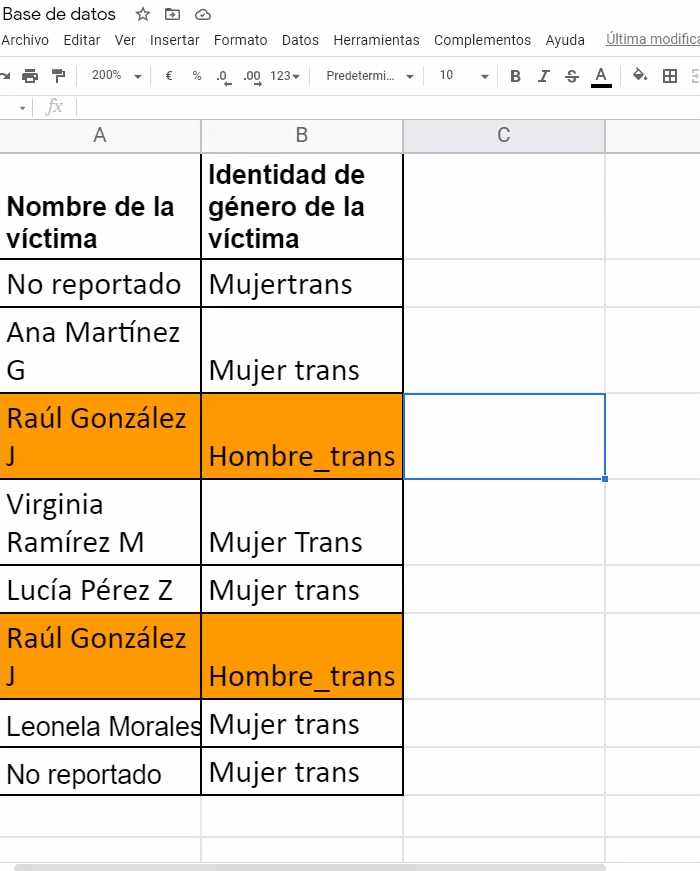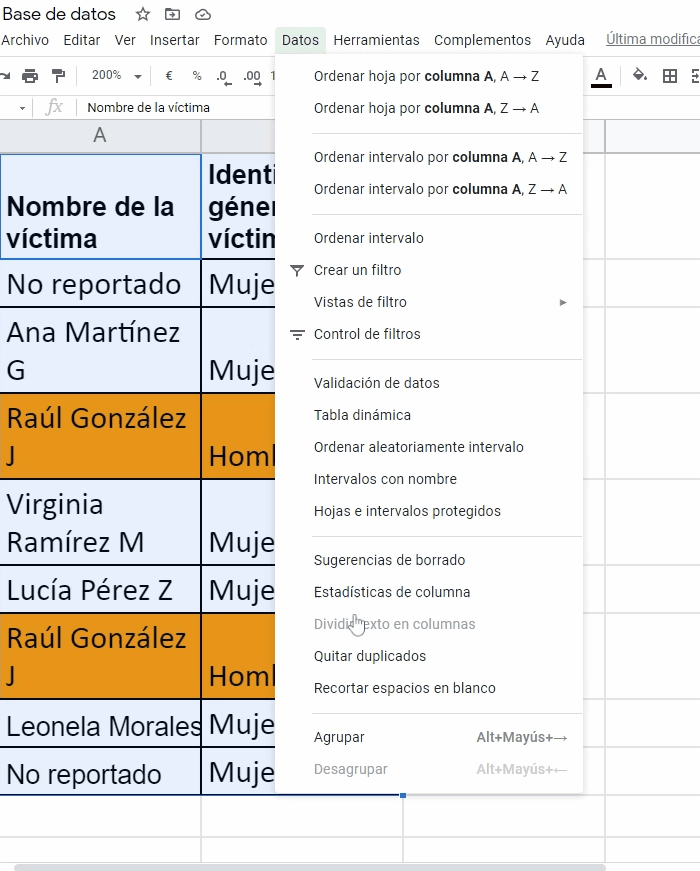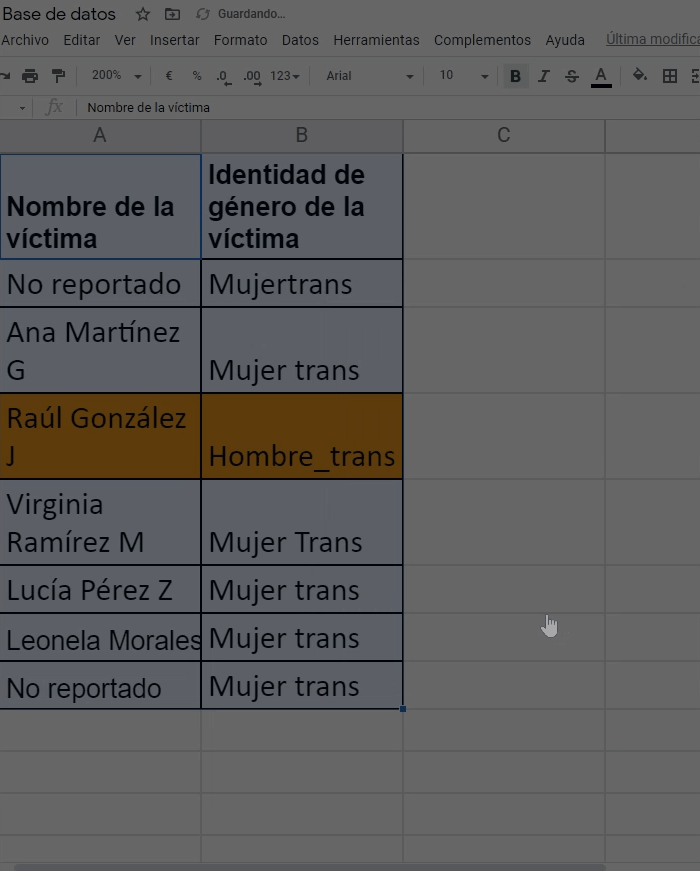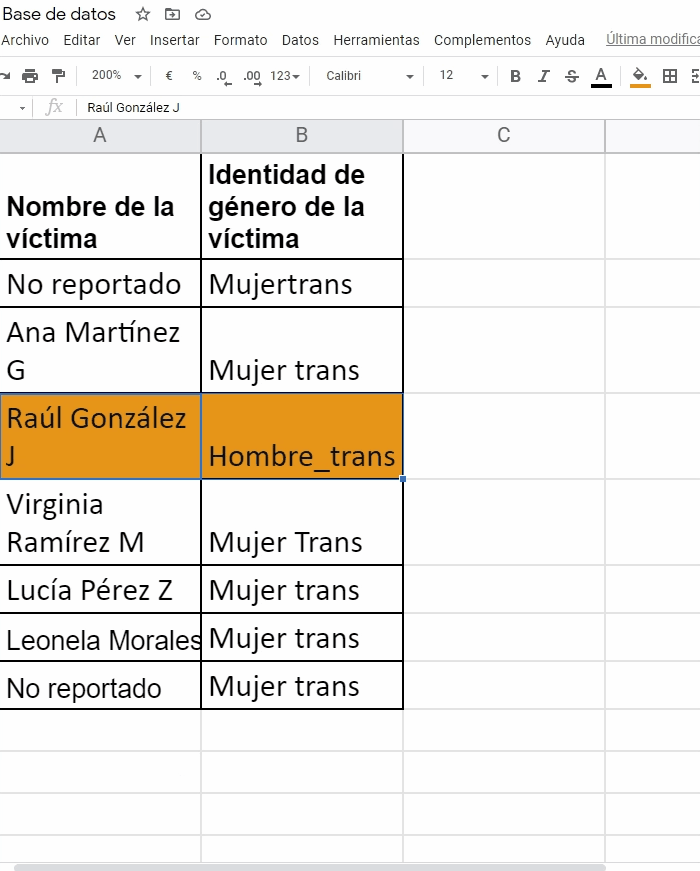
En la variable identidad de género de la víctima escribieron de tres formas distintas: Mujer trans: Mujertrans, Mujer Trans, Mujer_trans. Deben elegir una sola forma para estandarizar
En la fecha del crimen hay un error: 04&03/2021
En el lugar del hecho: Hotel aparece con ñ
En el lugar del hecho escribieron: Domicilio de la víctima y Casa de la víctima. Deben elegir una sola forma para estandarizar
Finalmente, el caso de Raúl González J está repetido
Ana y Francella, revisaron su diccionario de datos y coincidieron en que para la variable de identidad de género, la forma correcta de estandarizar su valor es Mujer trans.
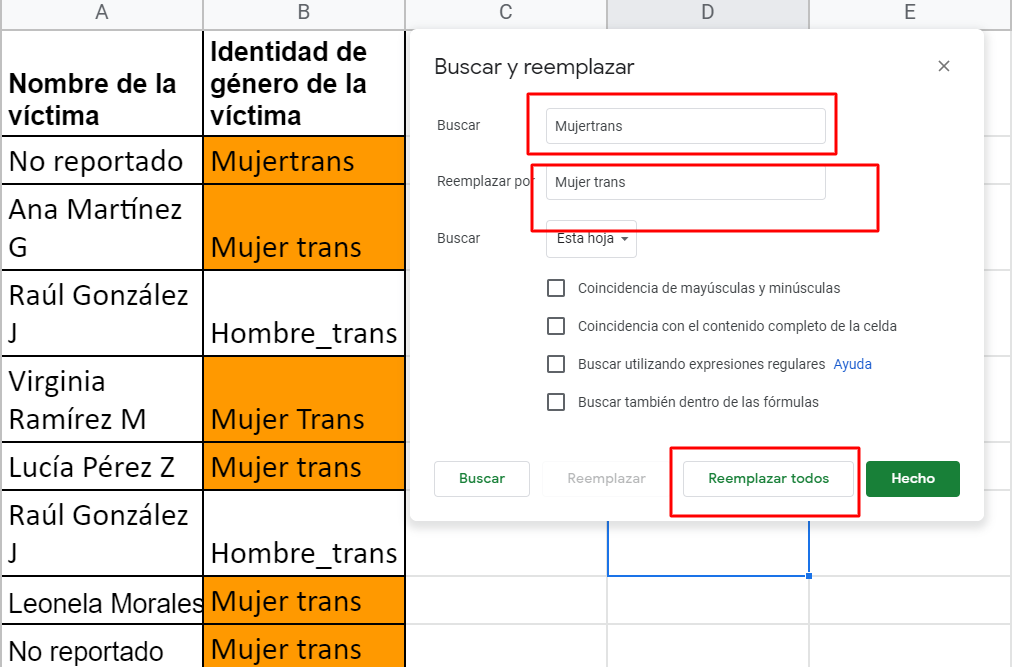
Para estandarizar y automáticamente cambiar a Mujer trans las otras formas en que escribieron esa categoría (Mujertrans, Mujer_trans) van a su hoja de cálculo de Google y acceden al comando: BUSCAR/ REEMPLAZAR, que se activa oprimiendo, simultáneamente, las teclas:
CTRL y F
Ana y Francella siguen estos mismos pasos en la imagen de arriba para cambiar la palabra hoteñ por hotel, corregir el & en la fecha por un / y para estandarizar Casa de la víctima por Domicilio de la víctima
¿Cómo quitar duplicados?
El siguiente paso que siguen las activistas es remover el caso duplicado de Raúl González J. Para evitar contar dos veces a esa persona, ambas seleccionan todos los rótulos con los nombres de las variables y también todas las celdas que contienen los datos de la base. Luego acceden al menú “Datos” de la hoja de cálculo y eligen la opción de “Quitar duplicados”, tal y como se muestra en el ejemplo a continuación:
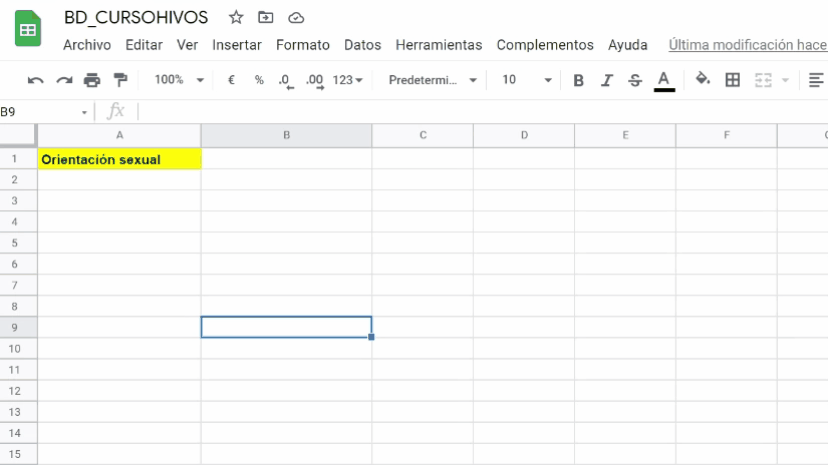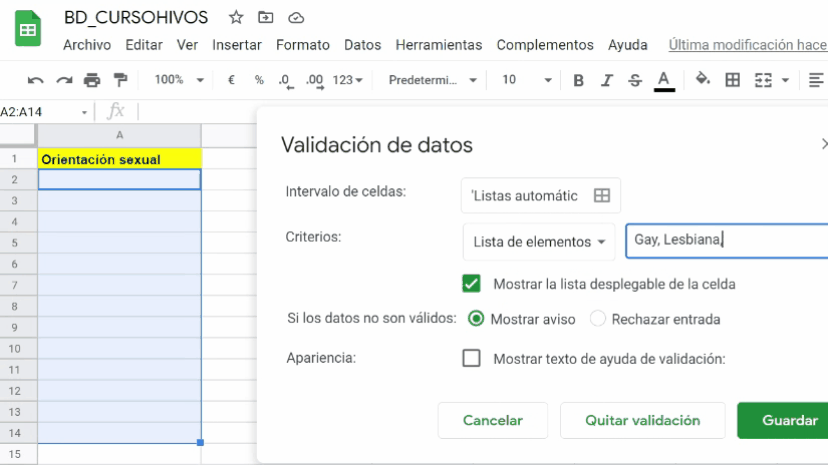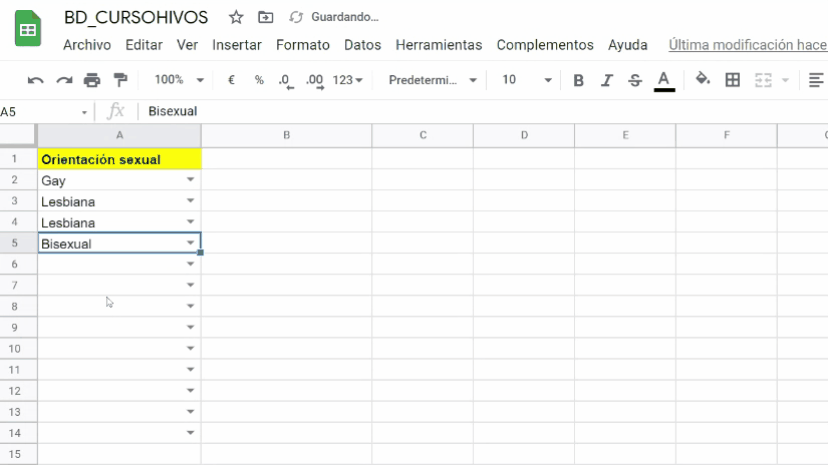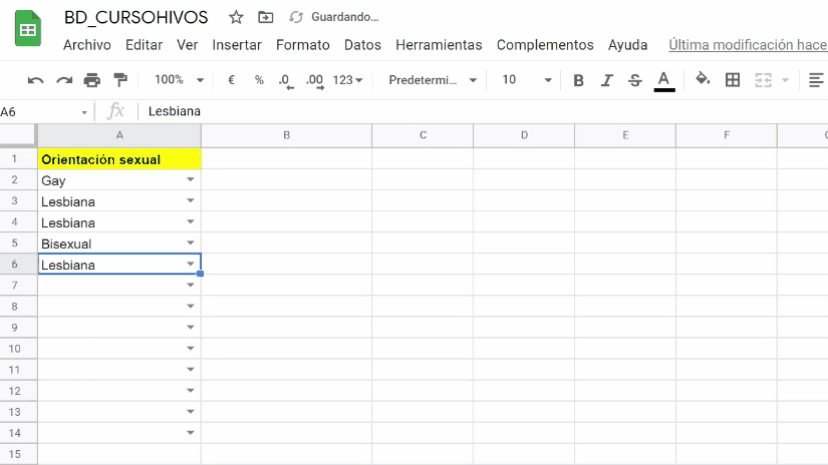
Crear listas para validar datos que adopta una variable
Las listas desplegables en hojas de cálculo con una de las mejores maneras de evitar que quienes introducen información en tu base, incluyan datos con errores de tipografía o fuera de los definidos en tu diccionario de definiciones. Las listas desplegables permiten que los usuarios elijan solamente un elemento preestablecido por tí en tus listas, tal y como muestra el siguiente video:
Hasta este punto del curso, ya has cruzado todos los puentes que te permitieron aprender a sistematizar,organizar y limpiar datos. Ahora, llegó el momento de analizarlos o de entrevistarlos -como a mí también me gusta llamar a este paso-. Analizar o entrevistar a una base de datos es, fundamentalmente, obtener información mediante preguntas. Es un proceso similar al de elaborar un cuestionario para luego, con ayuda de herramientas como los filtros o las tablas dinámicas en tu hoja de cálculo, extraer las respuestas desde tu base de datos. El objetivo fundamental del análisis es encontrar información y conocimiento que revelen algo interesante para tu investigación y para tu público meta.
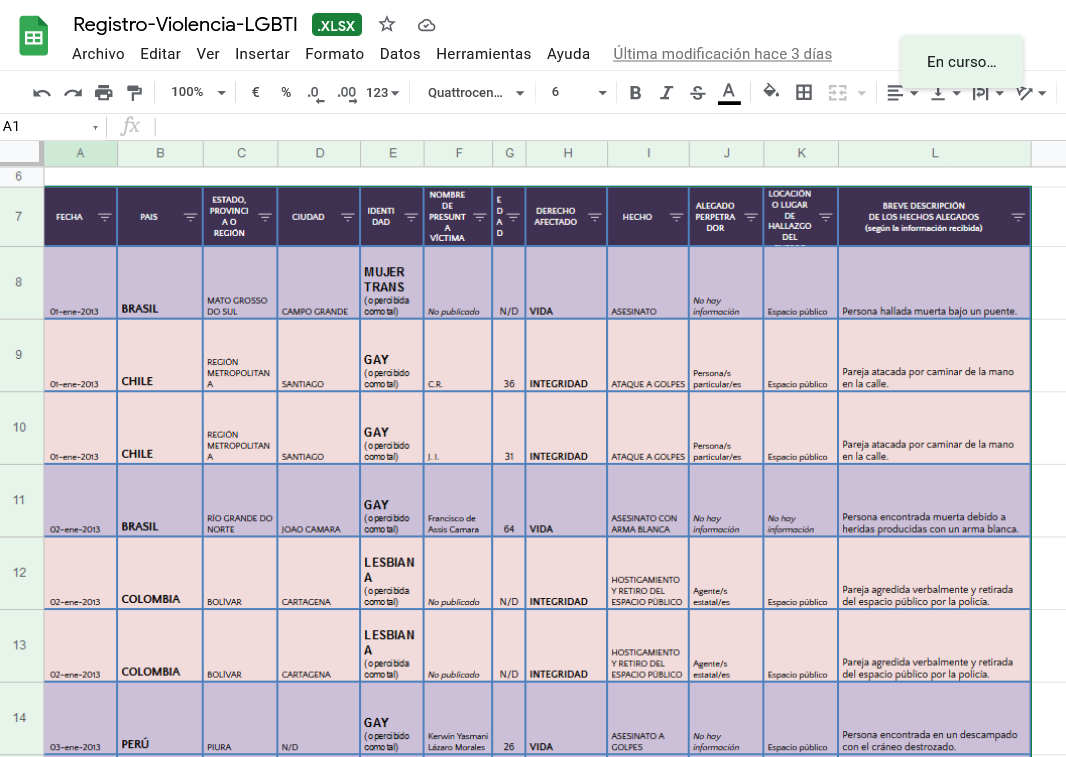
Para esta tercera parte del curso utilizaremos la base de datos de El Registro de Violencia LGBTI, recopilado por la CIDH en distintos países de América Latina entre 2013 y 2014.
Uso de filtros para encontrar respuestas rápidas en bases de datos
En una base de datos hecha en hojas de cálculo de Google, los filtros son indispensables para encontrar información de interés (subconjuntos de datos) dentro de la gran masa de cifras que contiene el archivo.
¿Cómo crear un filtro?
Supón que Alex y Andy , activistas por los derechos humanos, preparan un informe de investigación para evidenciar actos de violencia contra personas LGBTIQ+ en Centroamérica. Saben que la base de datos de El Registro de Violencia LGBTI documentó 770 hechos en toda América, pero elles quieren saber:
¿Cuántos de estos 770 actos de violencia ocurrieron en El Salvador, Honduras, Nicaragua, Guatemala y Panamá?
Para determinarlo, crean filtros dentro de la base de datos de El Registro de Violencia LGBTI
Pasos:
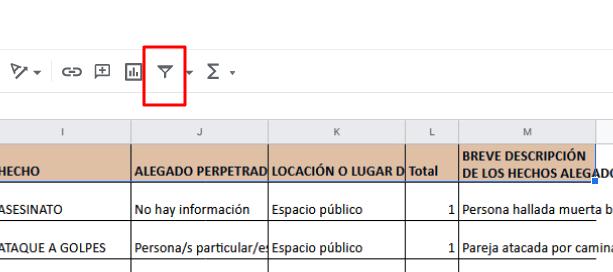
Marcan/seleccionan todos los rótulos de las variables en la base de datos, a partir de la columna A y hasta la columna M
Luego, seleccionan el icono del embudo/filtro que aparece debajo de la barra de Menú de las hojas de cálculo, en la esquina derecha
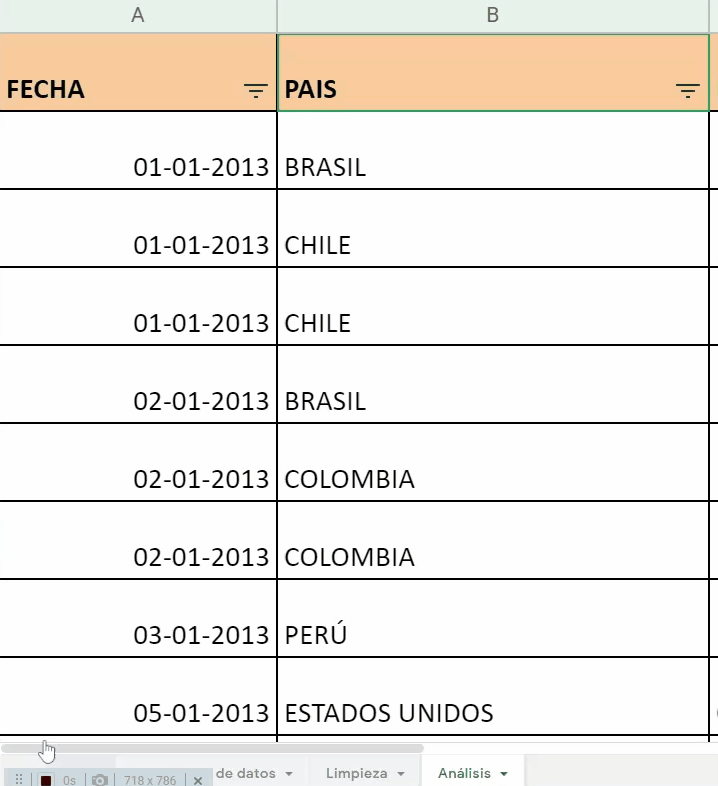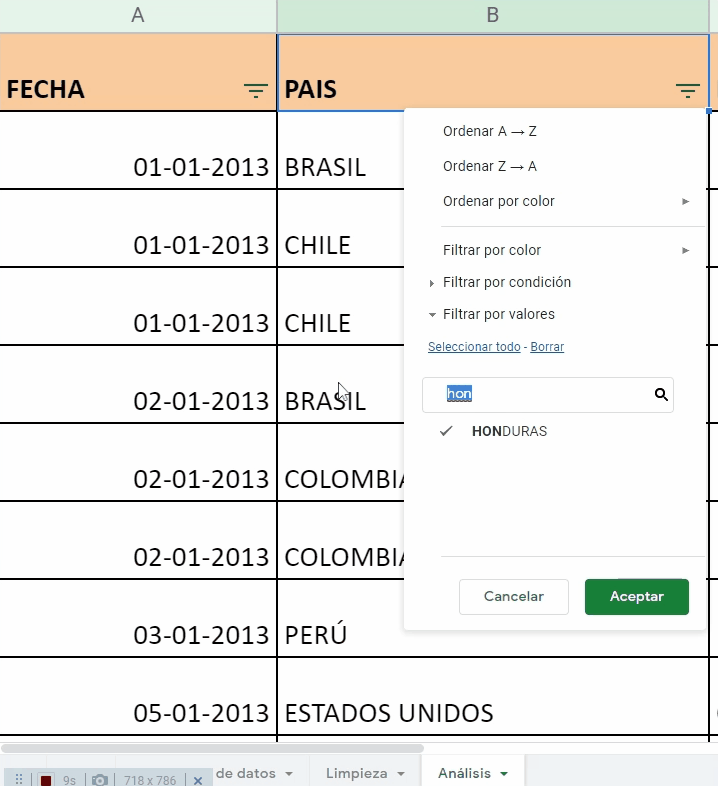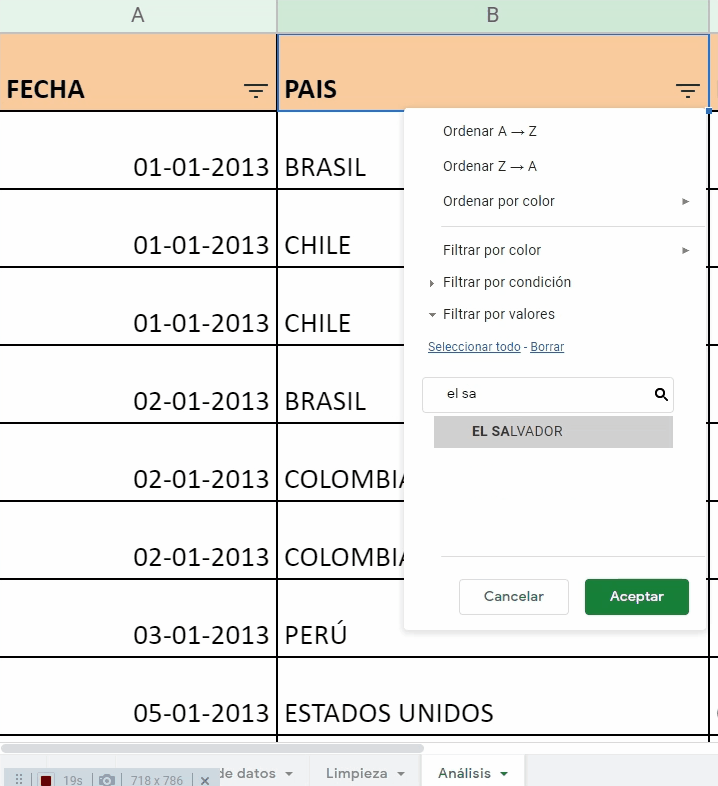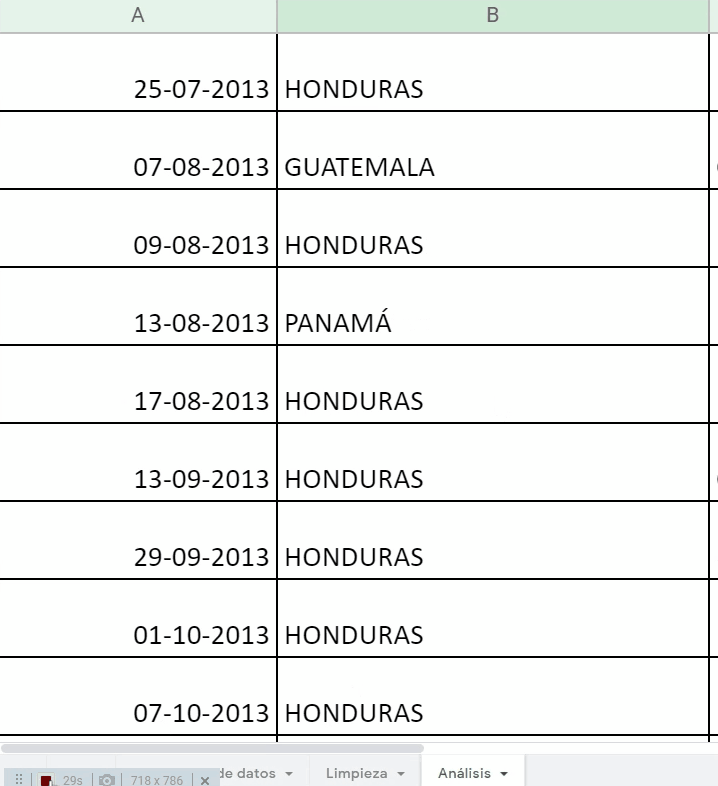
Posteriormente, van a la columna B, llamada País y abren el filtro para seleccionar, únicamente a los países de interés: El Salvador, Honduras, Nicaragua, Guatemala y Panamá.
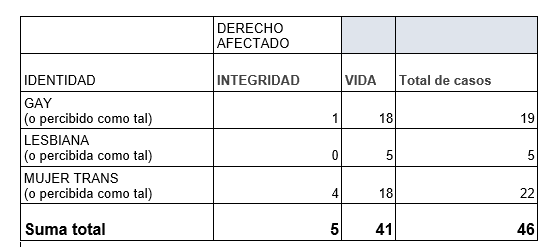
Una vez que han filtrado la base únicamente por los países de interés, Alex y Andy, van a la columna L, que contiene el Total de casos. La seleccionan completa y al final, en la esquina inferior derecha de la hoja de cálculo, aparece la sumatoria de 46 hechos de violencia ocurridos solamente en El Salvador, Honduras, Nicaragua, Guatemala y Panamá
Creando tablas dinámicas para cruzar información
Una tabla dinámica o pivote es una herramienta indispensable para hacer análisis de datos, es útil para resumir información, cruzar dos o más variables para encontrar respuestas complejas. Incluso permite hacer cálculos matemáticos y estadísticos básicos.
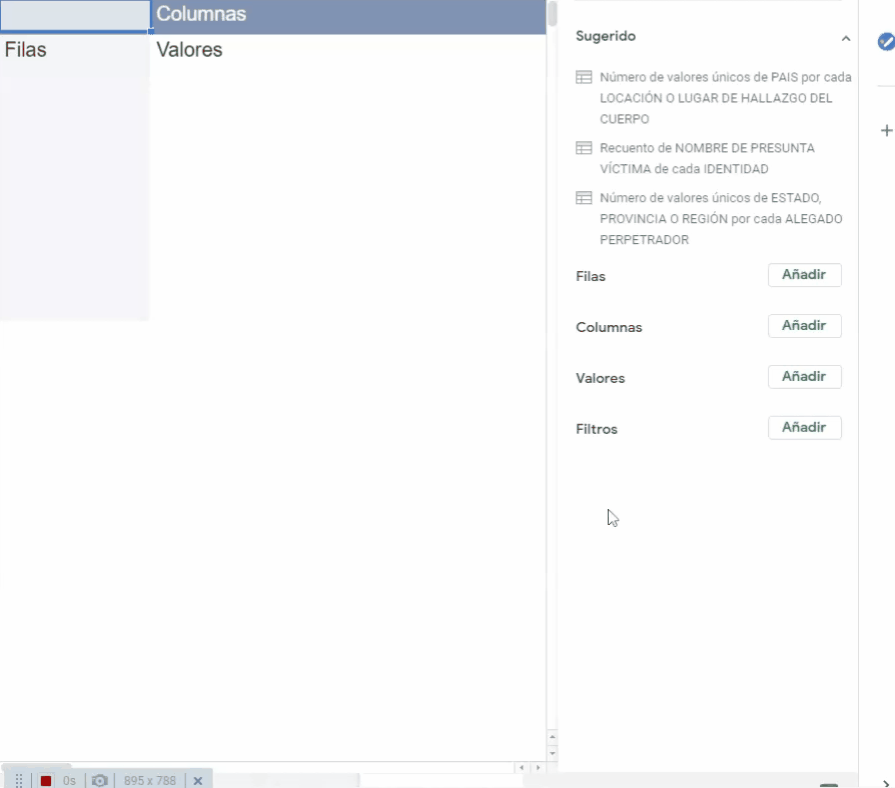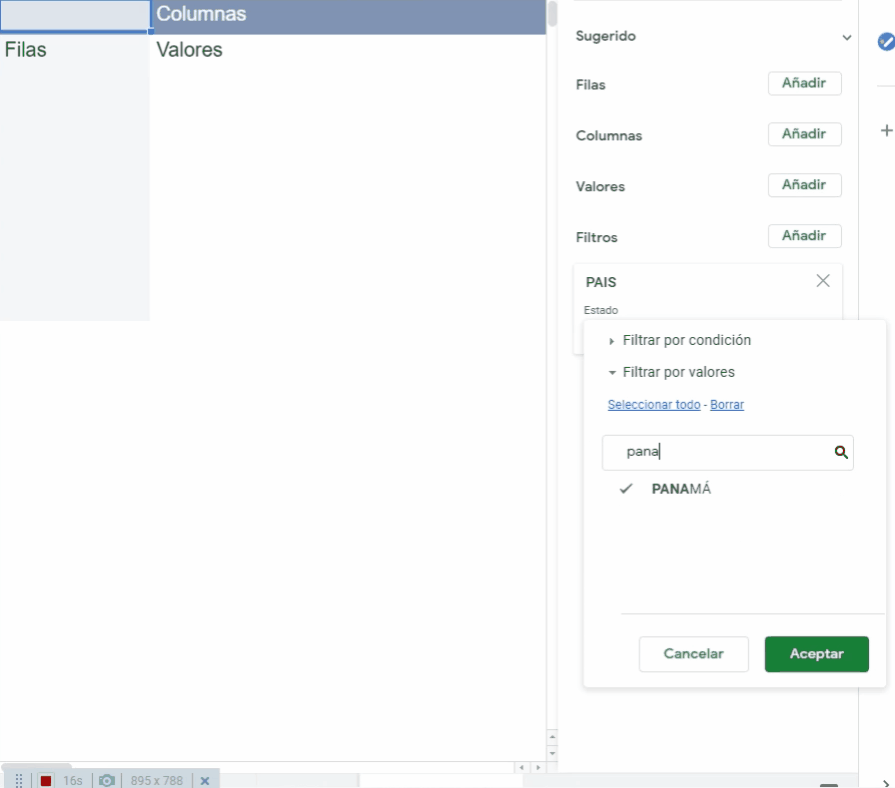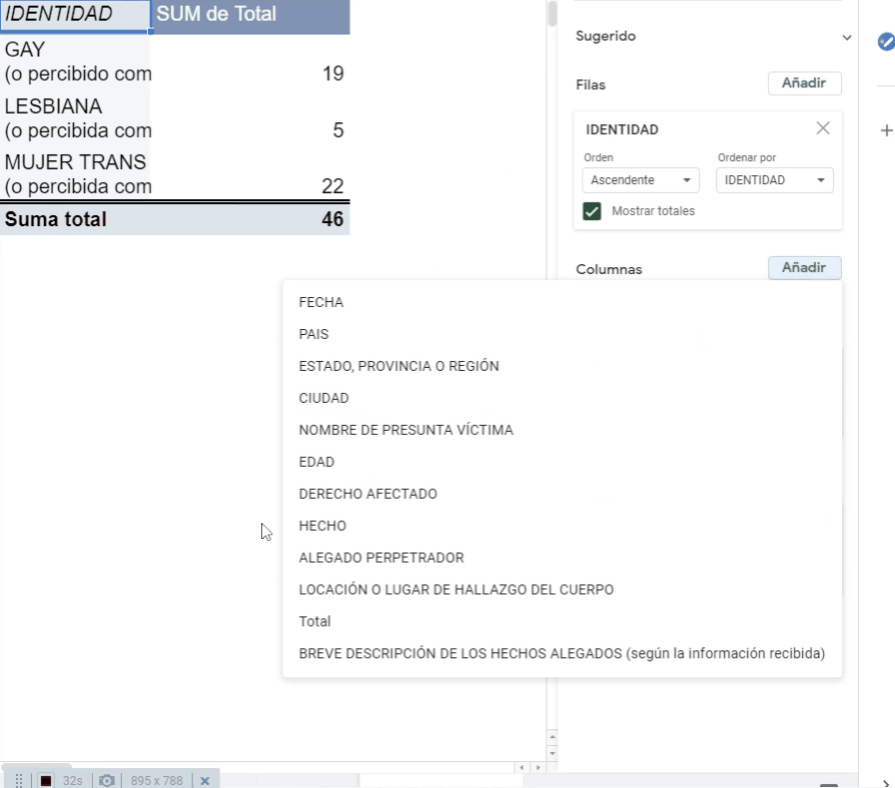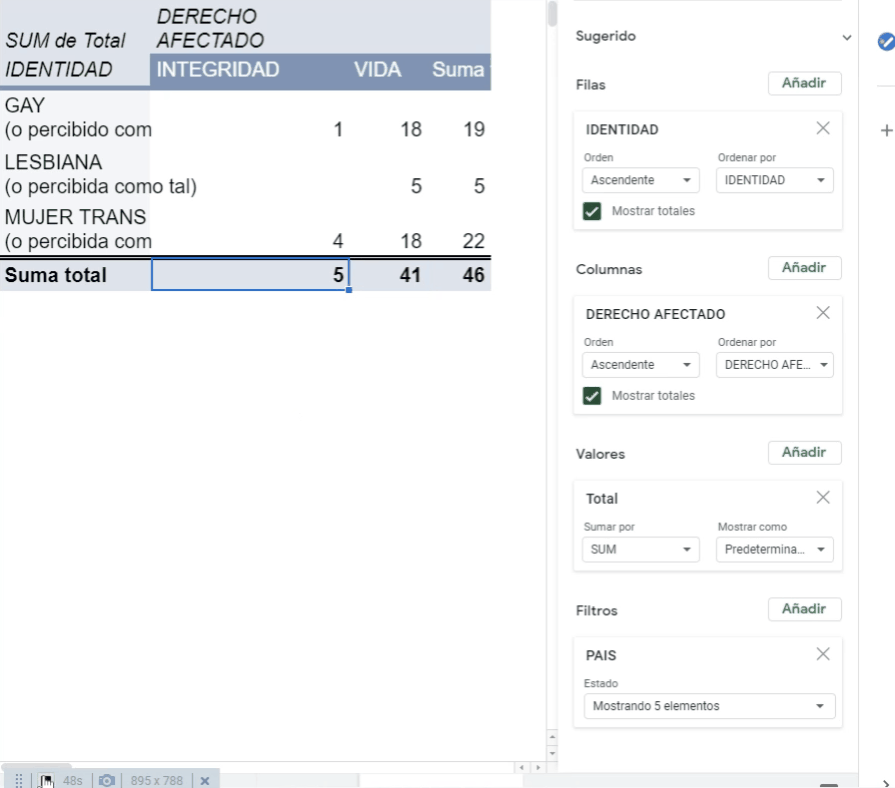
Por ejemplo, Andy y Alex desean saber cuántos de los 46 hechos de violencia registrados por la CIDH en Honduras, El Salvador, Panamá, Guatemala y Nicaragua se cometieron contra personas gay, lesbianas y trans. El resultado lo desean cruzar con el de la variable: Derecho que les fue vulnerado.
¿Cómo crear una tabla dinámica para hallar la respuesta?
Andy y Alex:
Seleccionan todos los rótulos de las variables de la base de datos.
Para hacerlo:
Usan el siguiente juego de teclas simultáneamente: SHIFT+CTRL+FLECHA DERECHA
Luego, para seleccionar todas las celdas, usan el siguiente juego de teclas simultáneamente: SHIFT+CTRL+FLECHA HACIA ABAJO
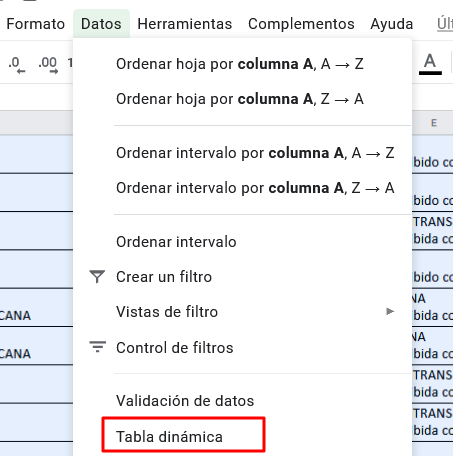
Una vez seleccionadas todas las columnas y celdas de tu base de datos , van al menú de “Datos” y seleccionan la opción “Tabla dinámica”
Crean la Tabla dinámica en una nueva hoja. El resultado que verán será como este:
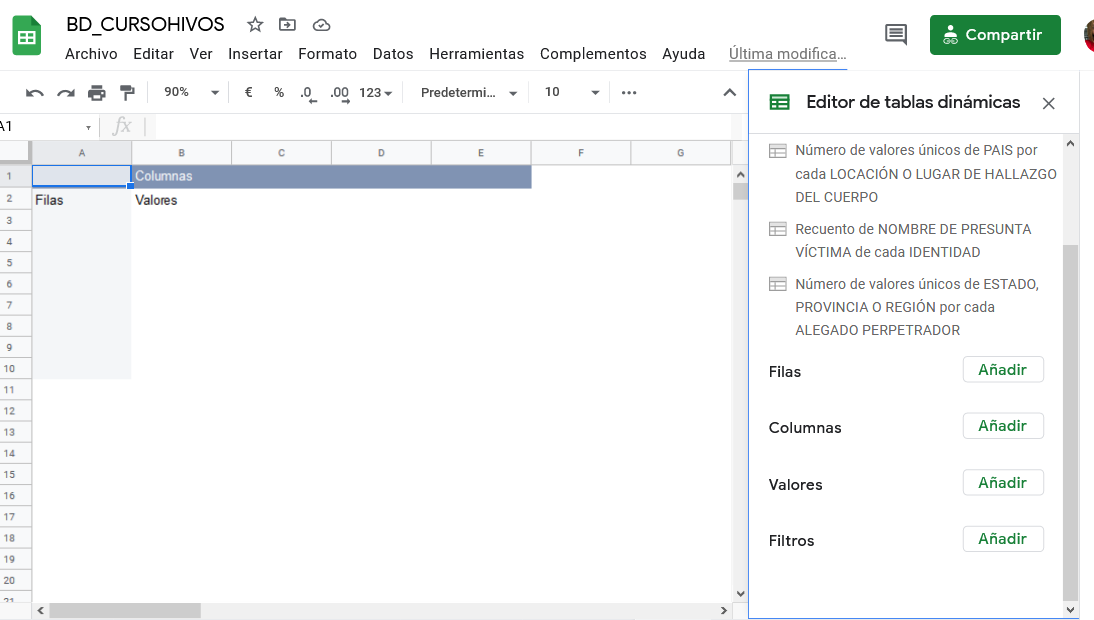
Ahora, usando las opciones de “Añadir” que aparecen en verde dentro de la interfaz del Editor de Tablas dinámicas, en los campos de Filas, Columnas, Valores y Filtros, Andy y Alex, seleccionan las variables que requieren para dar respuesta a su pregunta:
Después de hacer la tabla pivote o dinámica, Andy y Alex saben que de las 46 personas LGBTI afectadas por hechos de violencia en Honduras, El Salvador, Panamá, Guatemala y Nicaragua, la mayoría -22- eran mujeres trans, de las cuales 18 fueron asesinadas y a otras 4 se les afectó su integridad física.
IV Parte: Gráficos para analizar y comunicar conclusiones de los datos
¿Alguna vez has tenido un momento ¡Eureka!? Eureka es una exclamación para celebrar un descubrimiento, algo que nos deslumbra porque, ¡por fín! lo comprendemos. El origen del término proviene de una frase dicha por Arquímides, un famoso matemático griego, y aplica perfectamente para lo que un buen gráfico o infografía es capaz de producir en el cerebro humano. Un gráfico es una representación visual de una serie de datos, pero detrás de esa sencilla explicación hay una serie de codificaciones necesarias para que el cerebro pueda comprender -casi intuitivamente- el mensaje y la complejidad que encierra esa imagen. En esta clase conocerás algunas herramientas en línea para crear gráficos que te ayuden a representar, visualmente, la información contenida en tu base de datos.
Tipos de gráficos: Los tres clásicos
Los gráficos de barras verticales son los más comunes para presentar información, pero no por eso deben de ser marginados. Son fáciles de entender y permiten comparar información y sacar conclusiones rápidamente.
Los gráficos de barras horizontales también son fáciles de comprender y particularmente útiles cuando se trata de evidenciar datos categóricos.
Los gráficos de líneas muestran una serie de puntos conectados en una sola línea. Se usan para representar cantidades significativas de datos que reflejan la evolución en un periodo de tiempo. Pueden ser de una o varias líneas.
Además de los tres gráficos mostrados arriba, existen muchos otros para presentar información visualmente. Puedes consultar una galería completa de ellos y las recomendaciones para su uso aquí:
Herramientas para crear gráficos
Hoy en día, existen una serie de herramientas en línea que facilitan la creación de gráficos -estáticos e interactivos- para comunicar mensajes basados en análisis de datos.
Por ejemplo, Andy y Alex, los activistas por los Derechos Humanos que preparan un informe sobre violencia LGBTIQ+ en América Central, decidieron usar las mismas hojas de cálculo de Google para crear un gráfico que muestre la distribución de las distintas formas en que fueron atacadas o asesinadas las 46 personas de Panamá, Honduras, El Salvador, Nicaragua y Guatemala que aparecen en la base de datos de de El Registro de Violencia LGBTIde la CIDH.
Hojas de cálculo de Google
Más sitios para crear gráficos en línea
Datawrapper
Flourish
Infogram
V Parte: Comunicación con datos
Has llegado al final del curso. En el camino, aprendiste de datos, variables y los valores que adoptan, diccionarios de datos, cómo estructurar una base de datos extrayendo información manualmente de diversas fuentes. También a limpiar datos, analizarlos y, por último, a crear gráficos para comunicar tus hallazgos.
Lo que resta son algunos consejos para que contruyas una narrativa que de el mejor contexto e insumos a tus usuarios para que comprendan por qué es importante visibilizar la violencia basada en odio o prejuicios contra las personas LGBTIQ+
Cada vez que vayas a elaborar un reporte basado en análisis de datos y gráficos, recuerda:
Explique las cosas de manera sencilla, pero no les robes profundidad. Nunca subestimes la inteligencia de tu lector.
Evite la palabrería adornada que no significa nada. En esa categoría
también cae el abuso del lenguaje técnico, que denota que no
entendiste nada del tema o te da pereza pensar para acercarlo a tu
público.
Edita y revisa los textos siempre. Busca siempre que los títulos de tus gráficos presenten la conclusión más relevante que evidencian los datos.
Respeta las normas de redacción y ortografía
Da instrucciones claras sobre cómo usar los gráficos y para qué sirven.
Aplica la estructura introducción, desarrollo y conclusión para aquello que redactes.
Créditos:
Esta guía está disponible bajo una licencia Creative Commons Attribution 4.0. Cite cualquier uso de ella como: Fallas, Hassel. ILDA/HIVOS (2021). Guía de aprendizaje para recolección, análisis y uso de datos para prevenir y atender la violencia a causa de orientación sexual e identidad de género.