

Second part (Lea en español)
Integrity and data quality are not negotiable. Both qualities are the cornerstone that the philosophy of Business Intelligence and Data-based Investigative Journalism have in common.
A database complies with the integrity principle when it contains accurate, reliable, and complete data. In order to ensure the quality of that information, no typing or spelling errors in figures should occur, as well as repetitions or blanks.
Confirming that both principles are met is a critical factor that must be ensured before undertaking any analysis.
When a company, for instance, decides to implement Business Intelligence, beyond the choice of technologies, it should be guaranteed that it would be implemented based on quality and accurate data. It is the only way to generate reliable knowledge to help you make good decisions and increase the profitability and financial sustainability pursued.
In the case of data journalism, in order to develop it, the quality and the integrity of information are core aspects. It is the only way to transform databases into reliable knowledge whose public interest is useful for the audience, or reveals issues that were hidden.
In journalism, it’s a means to an end, not an end in itself, through which through analysis, we can find a news story with value for people.
Tools (software) are not an end per se; they respond to the extent of strategy and knowledge of the analyst to achieve results, monitor and follow them. Programs are also sought and implemented in accordance with the needs and challenges required by each project.
The purpose is to pull all that knowledge from databases to underpin journalism and pour it in publications where people can rely on to decide questions of safety, health, employment or education that affect their quality of life. Everything, I insist, based on quality and reliable data.

- «BI is an interactive process to explore and analyze structured information about an area (usually stored in a warehouse data), to discover trends or patterns from which to derive ideas and conclusions,» according to Gartner.
What is data integrity?
When working with databases, questioning them is the rule. Do not take for granted the integrity and quality of the same; no matter if they were generated by internal or external sources.
As a data journalist, I usually note that a database is like any other source that reporters confront day after day. It is prone to telling lies, hiding information, giving us a partial picture of a phenomenon and inducing mistakes.
Quite simply, databases are made by people. They can be unintentionally or intentionally mistaken and it is always advisable to keep this in mind before using them as a foundation for an investigation. Therefore, it is vital to check the integrity and quality of information, contrasting it with other data sources, documentary or even expert judgment on the issue.
Ensuring the integrity of the information that will sustain our research depends on three factors: accuracy, reliability, and integrity of data.
One fact is accurate when it is exact and has no inconsistencies.
For example, the date of birth, full name, and profession of each individual in a database must always be typed in the same way.
Let us consider this example of inaccuracy in the info on one same person:
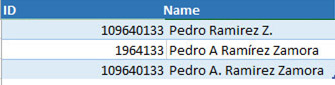
If these inaccuracies are not corrected we will arrive at false conclusions because, in the simplest case, we would be counting Pedro Zamora Ramirez as three distinct persons, when in fact it is just one.
On the other hand: where did data come from? What methodology was used and what purpose was sought? These are two vital questions to establish the degree of reliability we can have on these databases and determine how risky their use would be.
Finally, integrity depends on how complete the information is; if it contains all variables and attributes necessary for our analysis; if, when compare it with other databases we find precision and reliability.
What is data quality?
Data quality guarantees its value as an input to convert information into knowledge. In it, the processes and engineering techniques that help improve and minimize any potential flaws are fundamental.
For example, typing or spelling errors in figures, repetitions or blanks.
To achieve this, we need to know the traceability of data (the origin and different stages of production and distribution), its meaning, the purpose and context in which it was collected.
It is also important to have the data dictionary, vital to prevent misunderstandings about the nature of entities or variables that make up the base. The data dictionary contains the metadata or characteristics of the information that we will use.
For example, the 2011 Census Dictionary in Costa Rica allows knowing the name of the variables, their description, ranges, and codes. Thus, we have certainty that 1 in the variable Gender is Male and 2 corresponds to Female, to name just a few cases.
However, despite all this care, it is always possible to have dirty data in our data warehouse (with inconsistencies or repetitions, for instance). When data-based analysis is done, there is always a risk that the quality may not be 100% optimal.
The important thing is to minimize that risk and, should it be assumed, it should be as low as possible.
A good practice in BI of paramount importance in Data Journalism as well, is to define the rules to determine the quality of data.
This makes more sense when you consider that Data Journalism thrives primarily from database from external sources (those of various government and state institutions, for instance.)
That quality cycle should include the definition of:
- Quality Rules: what to do with the lack of data, incorrect or repeated data, with different formats. Data are deleted, some statistical technique is used to bring them to reality (where feasible) or other sources are sought to try to complete them.
- The type of corrections to be applied to data are: elimination of misspellings, formats to store them, using the same nomenclature for an entity (ej, Assault with a firearm for all crimes registered in the database as Assault with gun or Assault with weapon).
- Check that the corrections were made and validated.
Maintaining the integrity and quality of data is a constant work.
Only on the foundation of a good upgrade of databases that serve as raw material can we actually produce knowledge to serve our audiences. One last recommendation: when you make your publication, do not forget to explain to your audience the process and methodology followed to work with databases.